
服务热线
服务热线
最近在阅读文献时,发现大家做回归的时候,普遍对面板数据清洗的概念理解不到位今天主要介绍一下个人总结的数据清洗的基本方法本文适用于使用stata及其他计量软件的本科生、研究生,祝大家都能做出理想的回归结果,顺利毕业~。
我总结的数据清洗,主要分以下三个步骤:一、数据导入表格整理如果你的数据量不是很大,在寻找数据阶段,就要做好初步的数据整理我们一般使用wind/国泰安/锐思/各类年鉴等数据库下载数据,下载好后打开excel格式观察一下,借助excel里的筛选、排序等功能将数据排列,附一张截图是我常用的排列格式:。
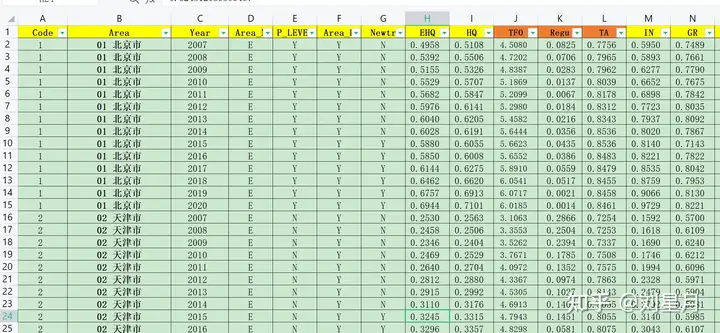
图1:excel导入stata前常用的数据排列格式之所以要这样排列,是为了实现以下几个功能:①可以很清晰地找到缺失数据,提前进行补齐;②个体变量用Code表示,一个个体附一个Code,与时间变量Year合在一起能够清晰地对每个时刻各个体的状态进行清晰标识,避免导入数据有些人设置面板格式后出现"unbalanced"或者"weakly banlanced"状态;③个体前加上数字,如“01 北京市”,这个主要是为了借助stata绘图、多种时序图放在一起时位置错乱;④除个体和时间变量外,依次排列年份变量、分类变量、因变量、自变量、控制变量等,在回归前做到思路清晰。
整张表格处理完之后,一定要检查一下你的表格,有没有excel提示报错的地方,如下:
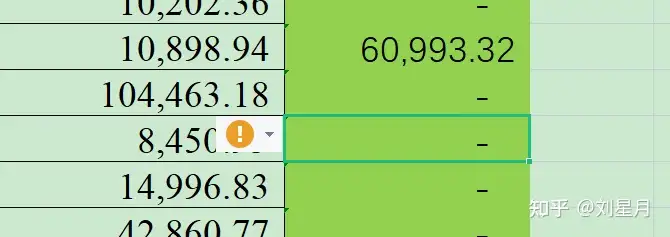
图2:excel提示报错这其实是一个非常小的点,数据库直接导出的情况下,如果报错不检查,直接导入stata其实很容易面板报错,所以数据量很大的情况下一定要注意检查,修改方法也十分简单:选中报错数据-鼠标右击-清除内容-格式及特殊字符。
一般这样都可以处理。
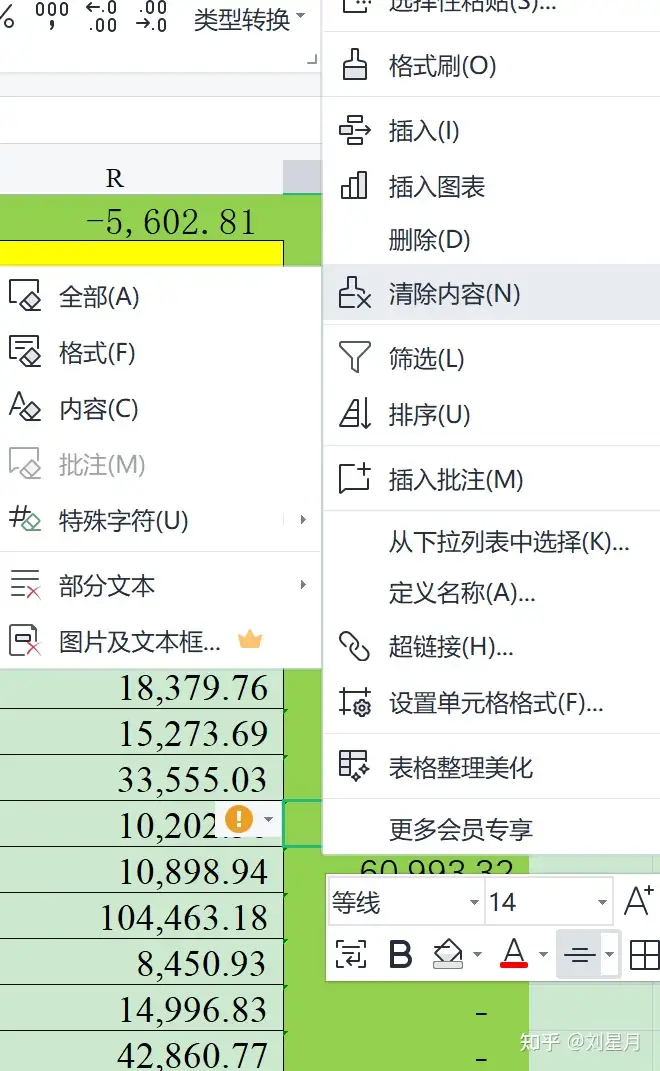
图3:报错数据处理二、数据初步处理整理完数据之后,你会发现你的各个变量有大有小、单位不统一我查了一些代码,发现一般会直接导入计算,似乎没有人提到这一步应该怎么办我的建议时,这时同比例扩大或者缩小、取对数等步骤在excel里直接进行,处理数据比较成功的标志应该是:。
观察整张表格,所有数据的分布大致在相似区间内,不会出现过多偏移这里介绍几种常用的方式:1.取对数:比如搜集了某地的占地面积指标,发现数据过大,可进行取自然对数处理2.比值:比如计算某地城镇化水平,搜集了某地的城镇化人口数后,除以该地该时间段内总人口数。
3.变量有特殊要求不能为0时:比如做SBM等模型时,产出投入数不能出现0,如果出现0,建议根据实际情况,将所有的变量统一向上平移最小单位,如0.0001,0.001,0.01,0.1,1等4.放缩倍数或者改变计量单位:。
比如某一指标单位是万元,发现数字过大,可以将该指标计量单位变为亿元;又或者该数据过小,可以对该变量同比例扩大十倍或者一百倍,等等提前处理好数据再导入软件,一来做到心中有数,什么变量用了什么处理方式,最后好真实披露在论文中;二来变量值分布在合理区间内,就。
能够大大减小回归后核心变量系数值过大或者过小的情况三、导入stata后处理数据导入后设置面板格式,注意提示是否是“strongerly banlanced”,不是的话,退回去检查数据,是的话,进行下一步。
导入后的处理主要包含以下步骤:1.初步回归验证核心变量显著性:用reg命令对被解释变量和解释变量进行验证,看解释变量的系数是否大致符合预期;如果显著且符合预期,进行下一步;如果不显著,显著性处理方式参照我的另一篇回答:Stata对面板数据用固定效应模型后核心解释变量不显著,怎么提高变量的显著性,可以从哪里入手?
Stata对面板数据用固定效应模型后核心解释变量不显著,怎么提高变量的显著性,可以从哪里入手?125 赞同 · 49 评论回答

2.如果结果显著,逐步控制时间、个体效应等。3.调节变量不显著的情况:对两调节变量必须进行中心化处理,命令是center,处理完后在进行交互,代入回归中。

扫一扫关注我们









